The term “synthetic passport” in the context of machine learning (ML) has a different meaning than in the context of financial fraud. While it can still relate to the latter, it most often refers to a type of synthetic data used to train and test ML models.

What is Synthetic Data?
Synthetic data is information that is artificially generated by computer algorithms or simulations. It is created to mimic the statistical properties and characteristics of real-world data without containing any sensitive or personally identifiable information (PII). In the context of “synthetic passports,” this means creating a dataset of fake, but realistic, passport images and information.
| Aspect | Description |
|---|---|
| Definition | In ML, a synthetic passport is a type of synthetic data—an artificially generated dataset of passport images and information. It’s used to mimic real passports without containing any real personal information. |
| Purpose | To provide a large, diverse, and ethically sourced dataset for training and testing ML models used in identity verification, document analysis, and fraud detection. |
| Key Benefits | Privacy & Compliance: Avoids legal and ethical issues related to handling real sensitive data. Data Scarcity: Provides a virtually unlimited source of data, including rare “edge cases.”<br> Bias Reduction: Allows for the creation of balanced datasets to prevent model bias. |
| Creation Methods | Generative Adversarial Networks (GANs): Two competing neural networks (generator and discriminator) work together to create highly realistic data. Variational Autoencoders (VAEs): Models that learn the underlying structure of real data to generate new, similar data. |
| Applications | Fraud Detection: Models are trained on synthetic data to identify forged or manipulated documents. Identity Verification: Models learn to authenticate a person’s identity by comparing their facial features to their passport photo. Border Security: AI systems can use synthetic data to learn to quickly scan and verify documents at border checkpoints. |
Why Are “Synthetic Passports” (Synthetic Data) Used in ML?
There are several key reasons why ML developers and researchers use synthetic data, including “synthetic passports,” to train their models:
- Privacy and Compliance: This is the most significant advantage. Real-world data, especially sensitive information like passports, is heavily regulated and difficult to obtain due to privacy concerns (e.g., GDPR, CCPA). Generating synthetic data allows developers to train models without the ethical, legal, and privacy risks associated with using real PII.
- Data Scarcity and Cost: Obtaining a large, diverse dataset of real passport photos can be prohibitively expensive and time-consuming. Synthetic data can be generated in massive quantities, on-demand, and with specific characteristics to meet the needs of a particular project. This is especially useful for creating “corner cases” or rare scenarios that may be underrepresented in a real dataset.
- Bias Reduction: Real-world data can be biased, leading to ML models that are unfair or inaccurate for certain demographics. By controlling the generation process, synthetic data can be created to be more balanced and diverse, helping to mitigate these biases and improve model performance.
- Model Validation and Testing: Synthetic data can be used as a ground truth “answer sheet” to validate the accuracy of an ML model. Since every piece of information in the synthetic dataset is known and controlled, developers can precisely measure how well their models perform.
- Creating “Edge Cases”: Real-world fraud attempts are often rare, making it difficult to train models to detect them. Synthetic data can simulate these rare “edge cases”—such as passports with specific types of damage, unusual fonts, or subtle forgeries—that are essential for creating a highly effective fraud detection system.
How Synthetic Passports Are Created
The creation of a synthetic passport dataset is a complex process that relies on advanced generative AI techniques.
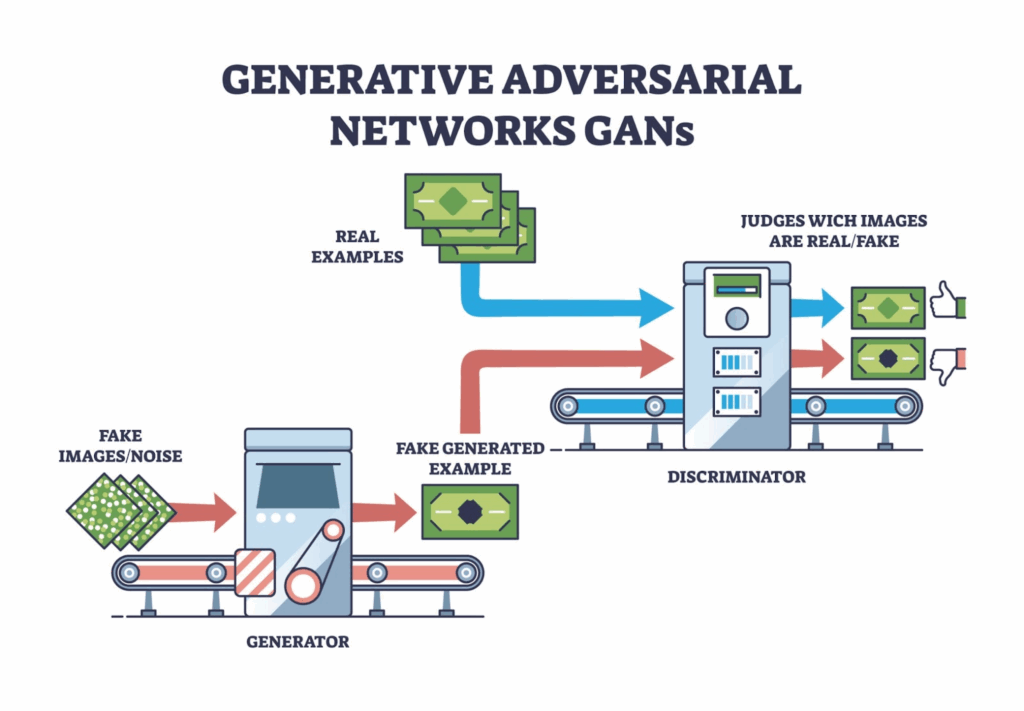
- Generative Adversarial Networks (GANs): GANs are a popular method for generating synthetic data. They consist of two competing neural networks:
- The Generator: This network creates new synthetic passport images from scratch.
- The Discriminator: This network tries to distinguish between the real data and the images created by the generator. Through this adversarial training, the generator continuously improves until it can create images that are indistinguishable from real ones.
- Variational Autoencoders (VAEs): VAEs are another type of generative model that learn the underlying structure of real data to generate new, similar data. They are effective for creating highly realistic and diverse datasets.
- Hybrid Methods: Many developers use a combination of techniques. For example, they might use a GAN to create a realistic face for the passport photo, a different model to generate the text and numerical data, and then use image editing software to combine the elements onto a passport template. This process often includes adding realistic imperfections like shadows, glares, or smudges to make the data more lifelike.
The Role of Synthetic Data in Combating Fraud
The use of synthetic data extends beyond training models to detect fraudulent documents. It is a powerful tool in the fight against all forms of fraud, including synthetic identity fraud itself. By using synthetic data to create realistic fraud scenarios, financial institutions can train their ML models to detect and prevent criminal activity more effectively.
Example Applications:
- Fraud Detection Models: Financial institutions use synthetic transaction data to train models that can identify new and evolving fraud patterns. Since real fraud data is scarce, synthetic data allows for a more comprehensive training set.
- Testing and Validation: When a new fraud detection model is developed, it can be rigorously tested on a synthetic dataset with known fraud cases. This provides a clear “answer sheet” to evaluate the model’s accuracy and performance before it is deployed in a live environment.
- Behavioral Analytics: ML models trained on synthetic behavioral data can identify suspicious patterns in user behavior, such as a user filling out an application with inconsistent data points or from an unusual location, which can be a key indicator of fraud.
FAQs
They allow safe training and testing of identity verification systems without exposing real personal data.
They are typically created using GANs (Generative Adversarial Networks) or other image synthesis models.
They protect privacy, reduce compliance risks, and provide large-scale data for model training.
No, synthetic passports are computer-generated for research and testing, while fake passports are illegal attempts at identity fraud.


